Entangled II by Scott Eaton.

Performance II: Skin on Repeat, NFT by Chrystal Y. Ding.
Ding is an artist/writer “interested in fluctuations in identity and embodiment”. She “uses machine learning to explore the impact of trauma & future technology on identity.”



StyleGAN2 trained on comics, study by Zach Whelan.
Agenda

Kyungja by Eunsu Kang (2017)
Finishing up ML Image Synthesis
- An Explanation of Convolution
- Text-to-Image and Google Colab
- A caveat about AI colorization
A Sampler of Diverse uses of ML in Art
- Human-Robot Interaction
- Neural Nets in Games
- Poetry
- Music
- Film
- Dance
Tools
Here is a Presentation about some ML Tools
Convolution: The Foundation of Convolutional Neural Nets
Convolution is a fancy-sounding name for an simple image-processing operation (such as blurring, sharpening, or edge detection). It underlies all of the recent work in Deep Convolutional Neural Nets and is worth taking a moment to understand. In the simplest terms, a convolution is an operation in which:
- each given pixel (1×1 gray)
- in a destination image (cyan)
- is computed by taking a weighted average of
- a neighborhood of corresponding pixels (3×3 gray)
- from a source image (blue):
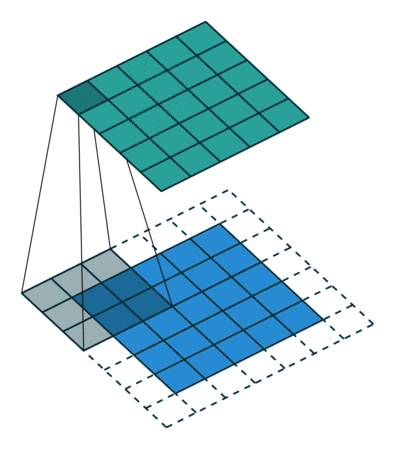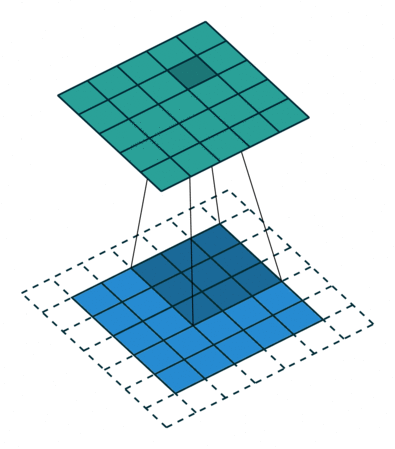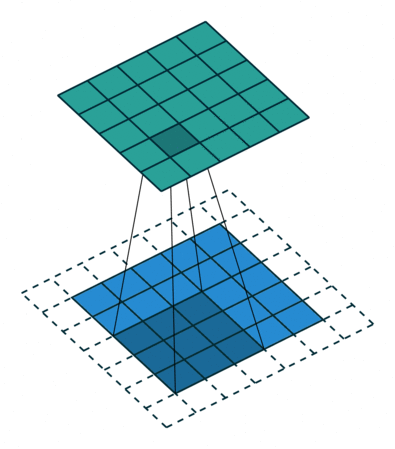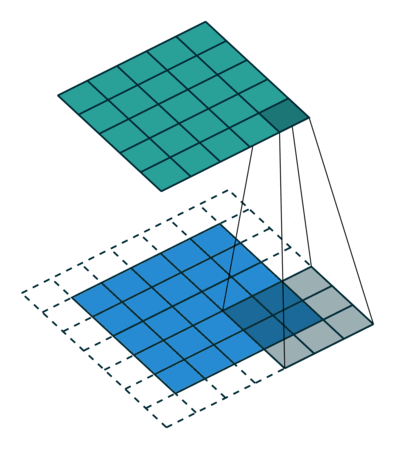
Let’s watch this nice explanation of “Convolution” from 1:12–2:50, and 4:31–6:13:
Here’s an interactive explanation that should make this even more clear:

Convolutional Neural Networks (CNNs) use convolutions at their lowest levels to detect features like points and edges. At the next-higher levels, the results of these detections (“activations”) are grouped in ever-more-complex combinations (textures→patterns→parts→objects). This CNN Explainer does a good job of opening the hood:
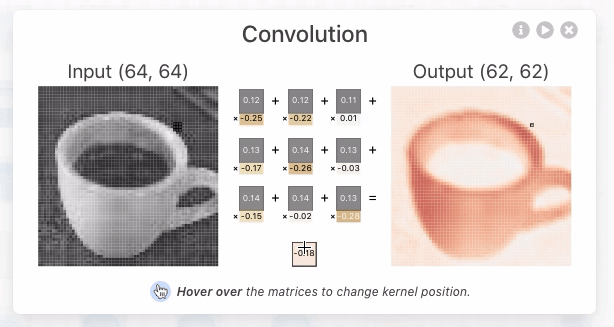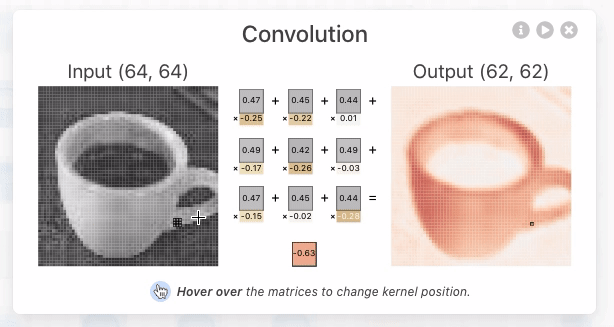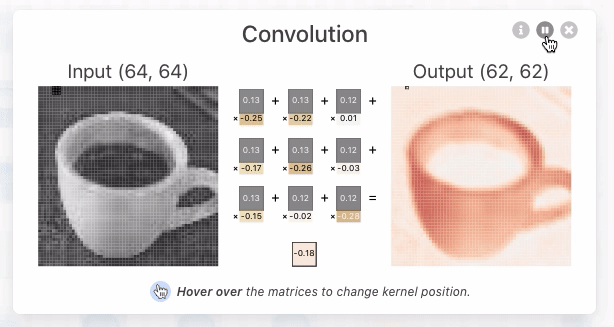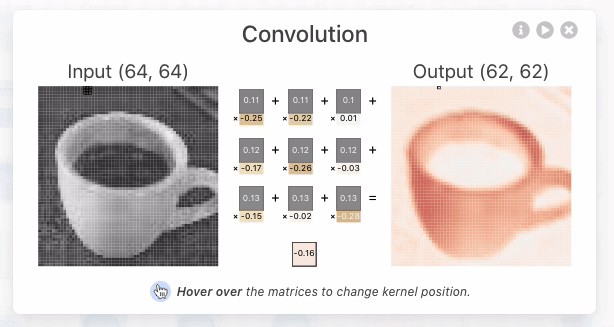
Image-to-Text: Bleeding Edge Techniques
For some time, AI researchers have worked on automatic captioning systems, computationally deriving text from images. Here are the results of one system called Neural Storyteller, developed in 2015. Note that the language model used to generate the text for these was trained on romance novels.


But what about the opposite? Is it possible to go from text to images? The Wordseye system allows you to do this (in the browser). It does not use machine learning to generate the images; rather, it combines a large library of readymade 3D models according to the nouns and prepositions in the provided caption.

In 2018, the AttnGAN network was developed. From text descriptions, it could synthesize images of things similar to ones it had been trained on— generally, objects in the ImageNet database.

Things have advanced significantly. In January of this year, OpenAI released a new model called “Dall-E” that could contruct novel forms in unexpected ways. Here it is synthesizing images of “an armchair in the shape of an avocado”:

Let’s take a moment to experiment with three extremely recent code repositories that build on this work. These have all been developed in the last month or so, and will give us the opportunity to run a project in a Google Colab Notebook, which is how many ML algorithms are developed:
- DeepDaze (Github; use “Simplified [Colab] Notebook”)
- BigSleep (Github; use “Simplified [Colab] Notebook” or Colab)
- Aleph2Image (Colab)
Here is a comparison of how each of these algorithms interpreted the sentence “cute frogs eating pizza” that I provided to them. How would you describe the difference in their results?
DeepDaze (“cute frogs eating pizza”):

BigSleep (“cute frogs eating pizza”):

Aleph2Image (“cute frogs eating pizza”):

Here’s a comparative study Simon Colton made of their output:



Human-Robot Interaction in Installation and Performance
Artists have been exploring ‘artificial intelligence’ in kinetic machines for more than 50 years. A landmark early work was The Senster (1970) by Edward Ihnatowicz, a large interactive sculpture that turned to face people who were making sound.

Sougwen 愫君 Chung has been using machine intelligence to create and collaborate with robot painting systems. Here’s her work from 2015, produced when she was a student:
Her work rom 2018:

And here is her work from just yesterday:

View this post on Instagram
New-media artist Stephanie Dinkins has been conducting an extensive series of performance-like interviews with a “social robot”, Bina48 (which, ahem, a wealthy entrepreneur created to emulate his wife). Dinkins has remarked, “When you train algorithms on limited data, what you get is holes in the results.”.

Artist Trevor Paglen collaborated with the Kronos Quartet on Sight Machine (2018), a performance in which the musicians were analyzed by (projected) computer vision systems. “Sight Machine’s premise is simple and strange. The Kronos Quartet performs on stage, and Paglen runs a series of computer vision algorithms on the live video of this performance; behind the musicians, he then projects a video that these algorithms generate. Paglen is an artist best known for his photography of spy satellites, military drones, and secret intelligence facilities, and in the past couple of years, he has begun exploring the social ramifications of artificial intelligence.”
With Kate Crawford, Paglen is also co-author of “Excavating AI” (2019), a extended essay and associated software suite which does a deep dive on the ImageNet image database (15M labeled images) that underpins an enormous amount of machine learning research and development. Crawford and Paglen ask: “What if the challenge of getting computers to “describe what they see” will always be a problem? In this essay, we will explore why the automated interpretation of images is an inherently social and political project, rather than a purely technical one”. They continue:
As we go further into the depths of ImageNet’s Person categories, the classifications of humans within it take a sharp and dark turn. There are categories for Bad Person, Call Girl, Drug Addict, Closet Queen, Convict, Crazy, Failure, Flop, Fucker, Hypocrite, Jezebel, Kleptomaniac, Loser, Melancholic, Nonperson, Pervert, Prima Donna, Schizophrenic, Second-Rater, Spinster, Streetwalker, Stud, Tosser, Unskilled Person, Wanton, Waverer, and Wimp. There are many racist slurs and misogynistic terms.
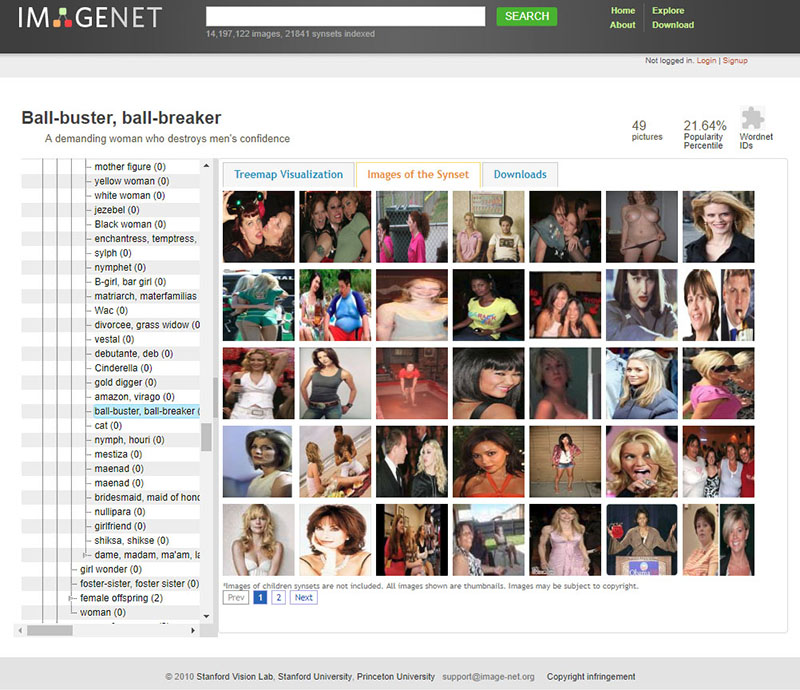
Of course, ImageNet was typically used for object recognition—so the Person category was rarely discussed at technical conferences, nor has it received much public attention. However, this complex architecture of images of real people, tagged with often offensive labels, has been publicly available on the internet for a decade. It provides a powerful and important example of the complexities and dangers of human classification, and the sliding spectrum between supposedly unproblematic labels like “trumpeter” or “tennis player” to concepts like “spastic,” “mulatto,” or “redneck.” Regardless of the supposed neutrality of any particular category, the selection of images skews the meaning in ways that are gendered, racialized, ableist, and ageist. ImageNet is an object lesson, if you will, in what happens when people are categorized like objects. And this practice has only become more common in recent years, often inside the big AI companies, where there is no way for outsiders to see how images are being ordered and classified.
Critical Appery
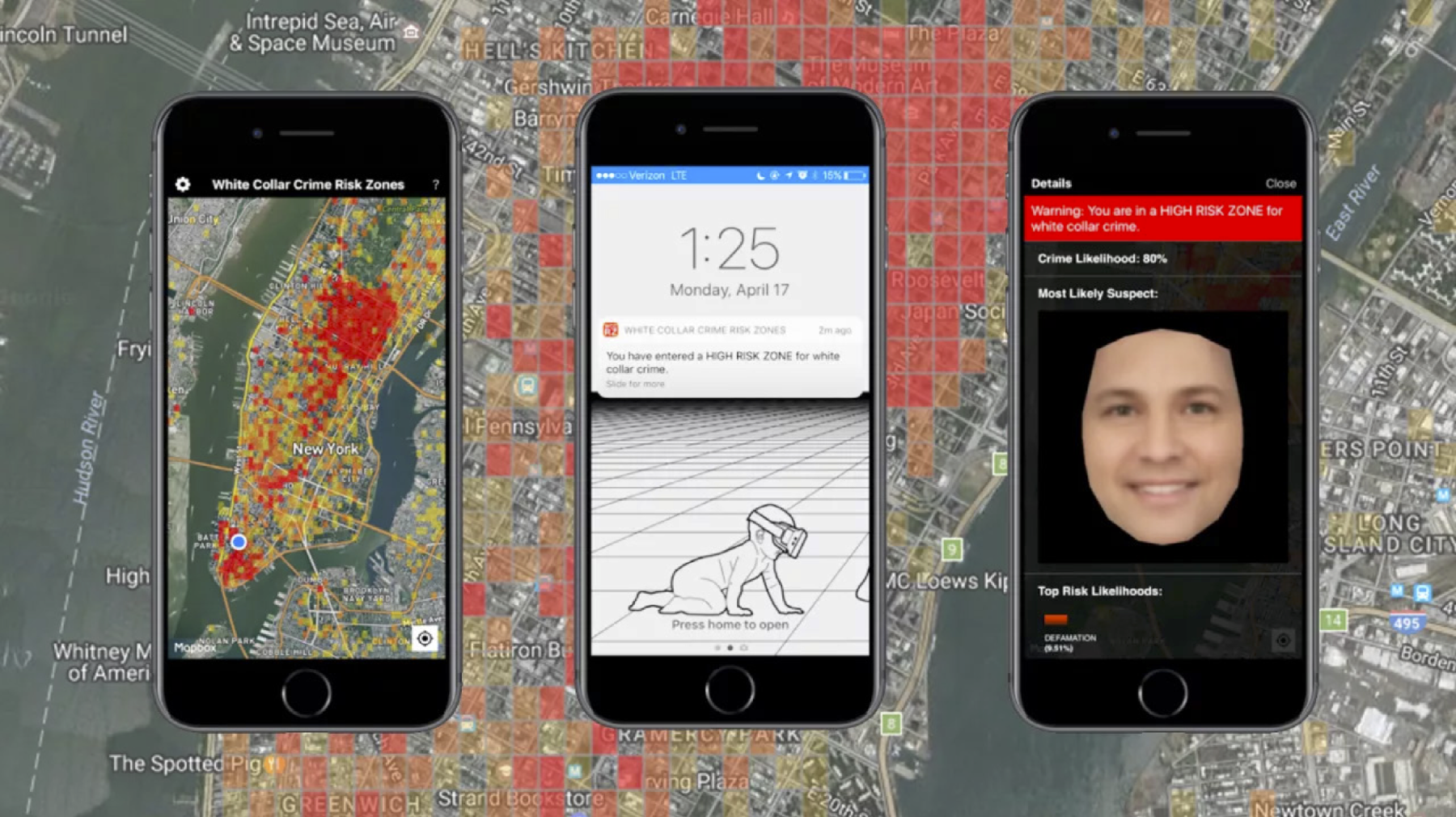
White Collar Crime Risk Zones by Sam Lavigne et al. uses machine learning to predict where financial crimes are mostly likely to occur across the US. The project is realized as a website, smartphone app and gallery installation.
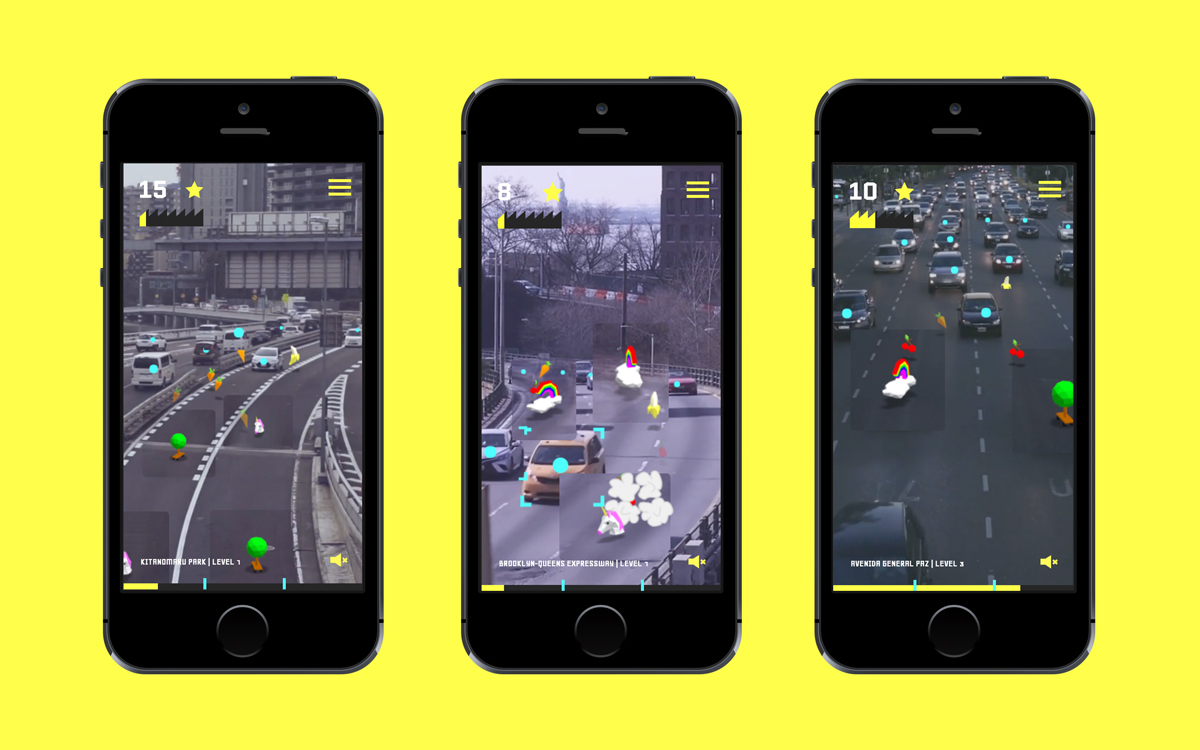
Neural Nets in Games
In the “Beat the Traffic” mini-game by Benedikt Groß et al., CNNs have been used to detect vehicles.
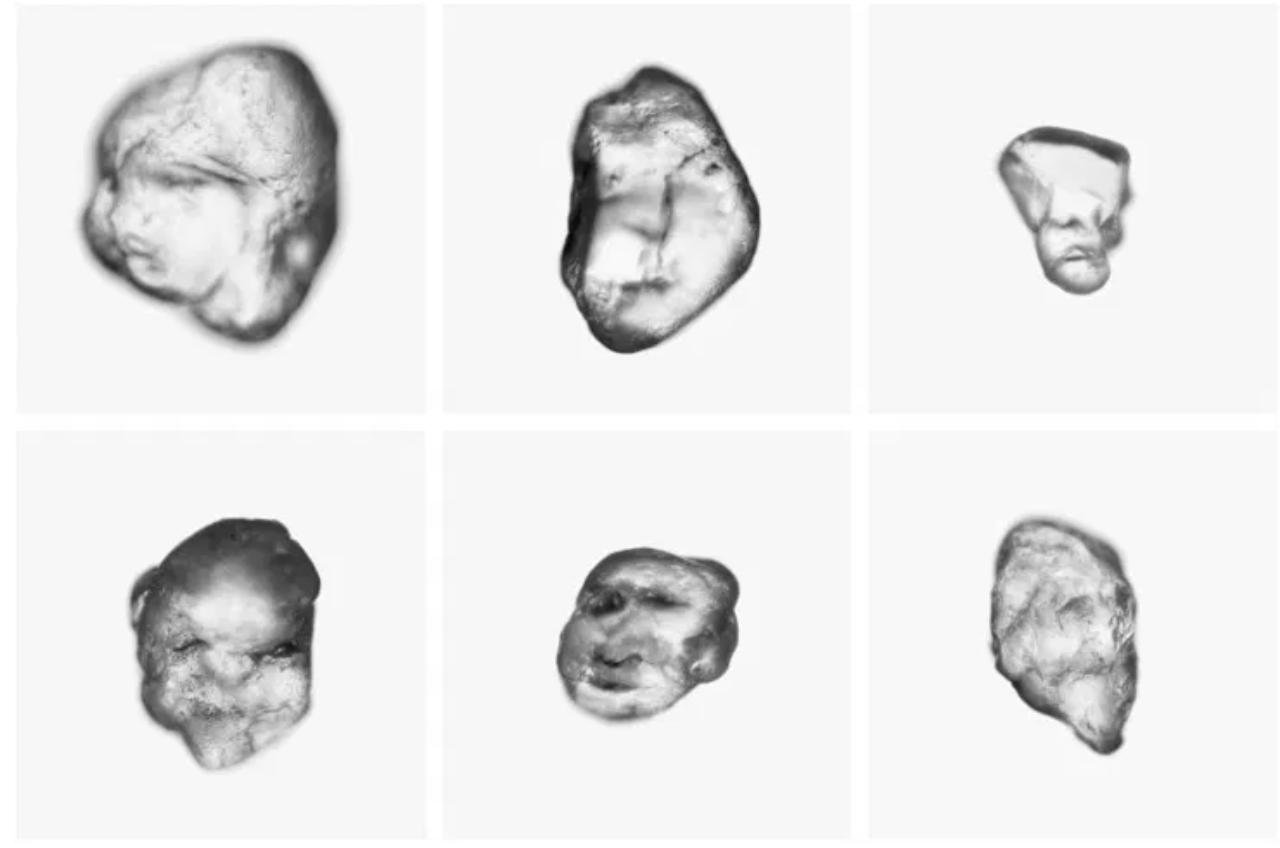
Absurd machine vision
Pareidolia, Maria Verstappen & Erwin Driessens, 2019. [VIDEO]
In the artwork Pareidolia, facial detection is applied to grains of sand. A fully automated robot search engine examines the grains of sand in situ. When the machine finds a face in one of the grains, the portrait is photographed and displayed on a large screen.
Text Synthesis and Poetry

Theo Lutz is credited as the author of the first text classifiable as a work of electronic literature. Here is his computer-generated “Stochastische Texte,” 1959:

Computer poetry (~1959) preceded computer graphics and visual computer art (~1964) by a few years. The first computers could only manipulate symbols (like letters and numbers). Here’s more early computer poetry by Brion Gysin (1960):
Janelle Shane is particularly well-known for her humorous 2017 project in which she trained a neural network to generate the names and colors of new paints:

A few days ago, she created a new work, Being vaccinated does NOT…
So a hobby of mine is introducing GPT-3 to online meme games that didn’t exist when its internet training data was being collected (the training data is currently only up till October 2019). It’s worked out well – without knowledge of the coronavirus pandemic, GPT-3 was able to do a reasonable job generating quarantine houses.
With vaccination underway but caseloads still high in many places, a new cautionary meme has emerged, for example:
Tweet by Emma Bolden: @emmabo being vaccinated does NOT mean you can start a theme park on an island populated with dinosaurs cloned from dna found in prehistoric mosquitoes, so preoccupied with whether you could that you didn’t stop to think if you should.
Shane generated similar memes with GPT3:
Being vaccinated does NOT mean you can hang out with bears and wolves and elk and eagles in their weird southern California forest hell. If for some reason you do this type of thing, you definitely can’t ride the raptors into battle or utilize their extremely keen eyesight. Not from that particular vaccine.
Being vaccinated does NOT mean you have to rub vanilla crème all over your body and change your species, but it wouldn’t be the worst idea, if you’re considering it.
Being vaccinated does NOT mean your child can ride on a bull made of solid gold to rodeo into a castle full of bad guys. Even if everyone else in St. Louis is doing it.
Being vaccinated does NOT mean you can travel through time and multiple realities. Fortunately you’re still the same good-hearted grade schooler you were before you walked out of that basement with two items in your hand. One was the ability to restore the Dragon Balls, and the other was the recipe for the world’s best green bean casserole.
Being vaccinated does NOT mean you can use an incredibly powerful magic necklace to turn yourself into a football player so you can smuggle some footballs into football practice so football players can play football.
Being vaccinated does NOT mean you can kidnap the Emperor of China, tear up some of your China-based robotics studies, mix in some magic, and fly around on robotic falcons shooting grappling hook crossbows that reel in the scarf of a big greased wizard. This is a bad idea.
The world’s foremost computational poet is probably Allison Parrish. Here is an astoundingly good video from 2015; let’s watch a few minutes starting from 1:30-4:30.
Music
The Infinite Drum Machine, Manny Tan & Kyle McDonald (2017). “This experiment uses machine learning to organize thousands of everyday sounds. The computer wasn’t given any descriptions or tags – only the audio. Using a technique called t-SNE, the computer placed similar sounds closer together. You can use the map to explore neighborhoods of similar sounds and even make beats using the drum sequencer.”
Filmmaking
Ross Goodwin: Sunspring, A Sci-Fi Short Film
Dance
Maya Man, PoseNet Sketchbook (2019). Maya Man is an artist and creative technologist based in New York, NY. After studying computer science and media studies at Pomona College, she joined the Google Creative Lab in New York as a ‘Fiver,’ the Lab’s one-year residency for early career creatives.
As a full-time creative technologist at the Lab, she worked on this collaboration with artist, choreographer, and dancing legend Bill T. Jones: Body, Movement, Language: AI Sketches, 2019:
More Reading on AI in Society
Deepfakes portend all sorts of mischief. Here’s how the recent Tom Cruise deepfake was made.

Systems that use artificial intelligence are quietly becoming present in more and more parts of our lives. But what does this technology really mean for people, both right now and in the future? Written in 2018 by Mimi Onuoha and Mother Cyborg (Diana Nucera), A People’s Guide to AI (PDF) is a comprehensive beginner’s guide to understanding AI and other data-driven tech.